背景介绍
Linux的栈内存管理相信大家都已经很熟悉了,针对栈内存的攻击也是比较常见的。然而对于堆内存的管理机制可能不太熟悉,针对堆内存的攻击也是比较困难的,所以我通过阅读各种资料以及Glibc的相关源码,对Glibc下的堆内存管理机制有了一定的了解,故在此记录下学习心得。
首先不同平台的堆内存管理机制是不一样的,我现在主要是针对Glibc的堆内存管理机制进行分析,Glibc的堆内存管理机制叫做ptmalloc。其他的一些比较流行的管理机制有:
- jemalloc(FreeBSD, Firefox, Android)
- ptmalloc(Glibc)
- tcmalloc(Google)
- libumem(Solaris)
Chunk structure
在Glibc的堆内存管理中,chunk是堆内存分配的基本的单位,它表示堆内存中连续的内存单元。比方说我们通过malloc(8)申请一个连续的8字节内存,则Glibc会分配我们一个大小为8(chunk size + previous size)+8(payload)大小的chunk。chunk分为allocated chunk和freed chunk。chunk structure在Glibc的定义如下所示:
1 | struct malloc_chunk { |
从上面的结构我们可以看出,如果一个chunk为allocated chunk,则它需要分配prev_size和size域,其中prev_size和size(表示整个chunk的大小,包括sizeof(prev_size)+sizeof(size)+sizeof(payload))用来在进行free()操作的时候将与该chunk空间上相邻的freed chunk进行合并,减少了堆内存空间的碎片化(具体怎么合并的在下面会具体介绍)。如果一个chunk为freed chunk的话,其相对于allocated chunk来说又多了两个域–fd和bk指针。因为freed chunk是通过多个链表结构将所有的freed chunk链接了起来,这样便于malloc函数快速找到合适大小的freed chunk,并且该这些表是双向链表(fastbins除外)。
所以对于malloced chunk来说,具体的内存区域如下所示:1
2
3
4
5
6
7
8
9
10
11
12chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| prev_size:Size of previous chunk, if allocated | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
在size域,有两个标志位,一个为M,一个为P。M表示该chunk是否是allocated chunk,P表示与该chunk空间上相邻的之前的chunk是否是freed chunk,如果该标识为0,表示previous chunk为freed chunk,则prev_size域表示previous chunk的大小; 否则如果previous chunk为allocated chunk,则记录previous chunk的大小就没有意义,此时就将prev_size域当做previous chunk的payload的一部分。
对于freed chunk来说,具体的内存区域如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
对于freed chunk来说,就多了两个域:fd和bk,这两个域分别指向该链表中的前一个元素和后一个元素。
Bins
在Glibc的堆内存管理中,bin是将一个个freed chunk链接起来的链表,而bins就是存储这些链表的一维数组。每一个bin都是双向链表。根据freed chunk的大小将其分为了不同的136个bin,其中有10个为fastbin, 62个small bin,63个large bin和一个unsorted bin。在malloc_state结构中,就定义了这些bin的数组,具体声明如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38struct malloc_state
{
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Statistics for locking. Only used if THREAD_STATS is defined. */
long stat_lock_direct, stat_lock_loop, stat_lock_wait;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. */
struct malloc_state *next_free;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
Fast Bins
在Glibc的堆内存管理机制中,一共有10个fast bin,每个fast bin链表中的所有freed chunk的大小(sizeof(prev_size)+sizeof(size)+sizeof(payload))都是相等的。每个fast bin都是一个单链表( )。Fastbins中最小的bin中的chunk大小为16字节,随后每个bin都增加8字节,所以最大的bin为80字节。需要注意的是,fast bin和其它的bin在free处理的时候有很大的不同,fast bin中的chunk的M标志都为1,因此在进行free处理的时候不进行freed chunk的合并操作(具体的合并操作在下文会具体介绍)。在每一个fast bin链表中,当有新的freed chunk需要插入时,会插入到该链表的尾部,删除也是从尾部删除,因此形成了一个先入后出(FILO)的策略。
Small Bins
Small bin的个数为62个,每一个small bin是一些大小相等的freed chunk组成的循环双向链表。当有新的freed chunk加入到该链表中,就加入到该链表的头部;如果要从链表中删除一个freed chunk时,则从该链表的为尾部删除,因此形成了一个先入先出(FIFO)的策略。第一个small bin中的freed chunk的大小都是16 bytes,后面每一个small bin的freed chunk的大小都依次增加8 bytes,因此最后一个small bin的freed chunk的大小为512 bytes。
Large Bins
与small bin和fast bin不同的是,每一个large bin中的freed chunk的大小不一定相等,其只是表示一个范围,在前32个large bin中,以64字节为步长,即第一个large bin中的chunk大小为512~575字节,第二个large bin中的free chunk大小为576~639字节。紧随其后的16个large bin依次以512字节步长为间隔;之后的8个bin以步长4096为间隔;再之后的4个bin以32768字节为间隔;之后的2个bin以262144字节为间隔;剩下的chunk就放在最后一个large bin中。
Unsorted Bin
只有一个unsorted sin,其主要存储两种chunk。一种是在malloc()操作中由于要分配的大小比freed chunk的大小要小,所以需要将该freed chunk进行分割,返回与要分配的大小相符的chunk,剩余的freed chunk则加入unsorted bin中;另一种是在free()操作之后,会返回一个新的freed chunk,该freed chunk(不在fast bin范围的chunk)则加入unsorted bin中。设置这一个bin的主要目的是扮演一个缓存层的角色以加快分配和释放的操作。
Top chunk
有一个特殊的chunk没有在以上的bins中,那就是top chunk,top chunk可以看做是heap的一个边界,当所有的bin中的chunk大小都不符合所请求的大小时,就从该chunk中进行分配,如果top chunk的大小大于所请求的大小时,则将top chunk分为两部分,一个是用户请求的chunk,剩余的部分就会成为一个新的chunk。否则,就需要扩展通过上移top chunk指针来扩展heap的大小(或者通过mmap来分配新的heap)。
Malloc
malloc函数是堆内存管理中最重要的一个函数之一,其在glibc中的包装函数为__libc_malloc(size_t)函数,在该函数中主要是进行一些准备性的工作–查找对应的arena结构,然后调用真正的分配内存的函数 _int_malloc(ar_ptr, bytes)。arena在glibc中的结构为malloc_state结构,主要存储bins,top chunk等结构。下面我们来看一下主要的分配函数_int_malloc的具体实现。
_int_malloc (mstate av, size_t bytes)
首先_int_malloc函数根据要请求的内存大小bytes来计算要请求的chunk的大小nb。主要是加上size和prev_size域和对齐的padding。
得到了要请求的chunk大小之后,首先判断该chunk的大小是否在fast bins的范围内,如果在它们的范围内就在fast bins中找到大小相符的chunk来分配。

如果要请求的大小不在fast bins范围之内或者相应的fast bin链表为空,则会判断其chunk size是否在small bins的范围之内,找到对应的small bin,取出该small bin尾部的那个chunk进行分配。

如果请求的大小是一个比较大的请求,则将fast bins进行合并。其要做fast bins合作的目的是为了避免有fast bins所引起的内存碎片化问题。在实际的操作中,程序一般都是分配小的内存或者分配大的内存,而不怎么会即分配大的内存又分配小的内存。所以这样的策略在实际的程序中效率还是很理想的。

由于unsorted bin中存储最近freed的chunk(包括第4步合并后的fast bins),接下来会遍历unsorted bin中的所有freed chunk,直到找到freed chunk大小和请求的大小相等的为止,或者循环了10000次也会停止遍历unsorted bin。遍历unsorted bin是唯一一个将freed chunk插入到相应的small bins和large bins的操作。在遍历的过程中,将当前节点chunk从unsorted bin中删除,如果chunk大小与要请求的chunk大小正好一致,则将该chunk返回,停止遍历,否则,将当前节点的chunk放入相应的small bins和large bins中。
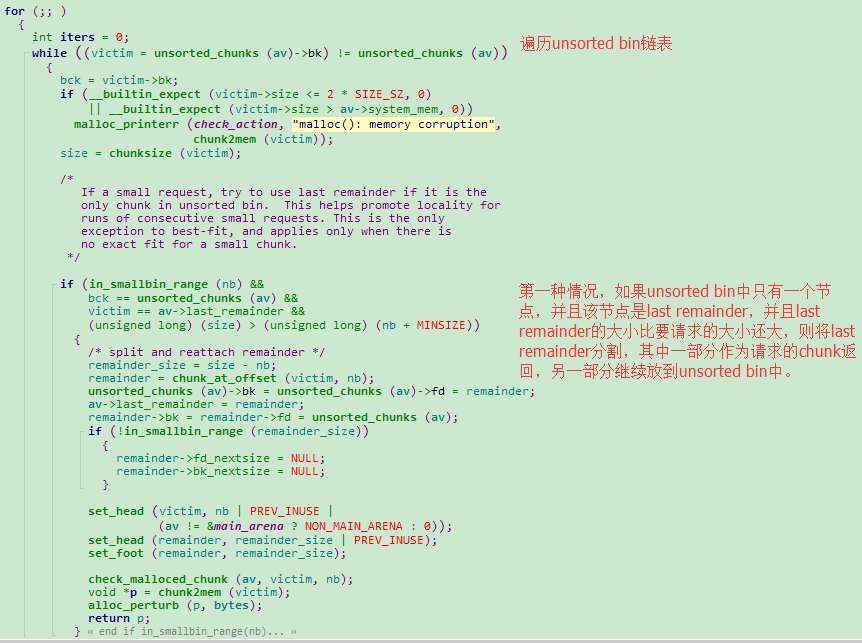

遍历了unsorted bin之后仍然没有找到合适的freed chunk,接下来回从large bins中进行查找,首先从large bin中的chunk大于等于请求的chunk进行查找。
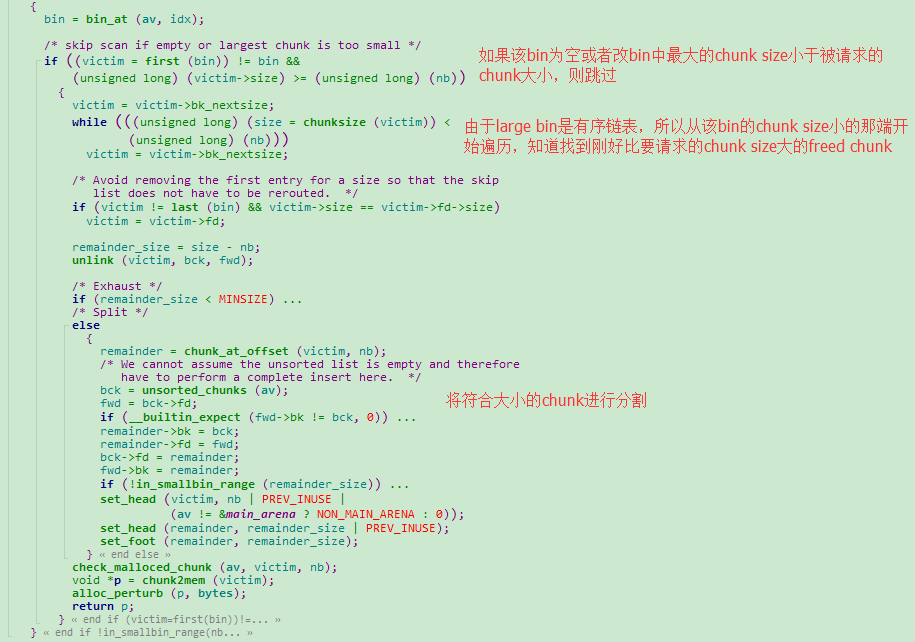
如果该large bin为空或者最大的chunk比要请求的chunk的大小还要小,则找到chunk size范围更大的large bin,进行的操作和刚才介绍的操作一致。
如果要请求的大小比large bins中的chunk还要大,则需要查看top chunk的大小了,如果top chunk的大小比要请求的chunk的大小要大,则分割top chunk,将剩余的chunk继续作为top chunk的一部分,否则判断是否还有fastbins,如果有fastbins,则将fastbins合并。以上各种查询都没有找到合适的chunk,则只能调用sysmalloc函数来进行分配。
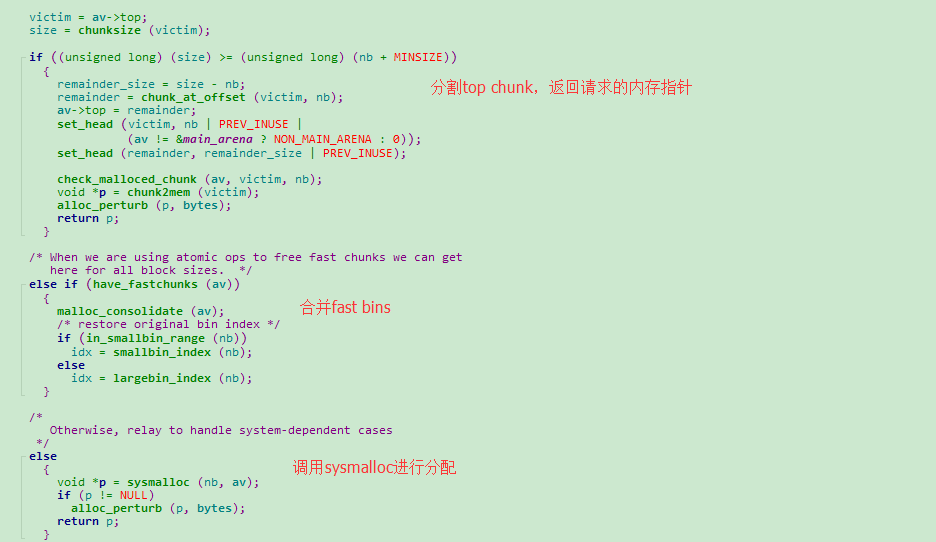
至此,malloc的分配的过程已经介绍完了,总结一下其查找过程就是fastbins->smallbins->unsortedbins->largebins->topchunk
Free
free函数也是堆内存管理中最重要的函数之一,堆内存的攻击也主要是针对free函数的进行的攻击。在glibc中,__libc_free(void mem)为free(void mem)函数的包装函数,其主要的功能也是找到malloc_state结构,然后再调用 _int_free(mstate av, mchunkptr p, int have_lock)函数。
判断p指向的地址是否在p+chunksize(p)指向的地址之前,如果不符合该规则的话就会抛出错误(“free(): invalid pointer”)。
判断chunk的大小是否大于MINSIZE或者是不是MALLOC_ALIGNMENT的整数倍,否则抛出错误(“free(): invalid size”)
判断要free的chunk的大小是否落在了fast bins的范围内,如果落在了这个范围内,则将该freed chunk加入到对应的fast bin中。

判断该chunk是否是mmapped,如果不是,就进行各种判断防止部分针对free操作的攻击。
- 判断要free的chunk是否是top chunk,如果是,则抛出错误(“double free or corruption (top)”)
- 判断next chunk在内存中是否在arean的范围内,如果不是,则抛出错误(“double free or corruption (out)”)
- 判断next chunk的P标志是否为真,如果不是,则抛出错误(“double free or corruption (!prev)”)
- 判断next chunk的大小是否正常范围之间,如果不是,则抛出错误(“free(): invalid next size (normal)”)

然后将与free的chunk与其相邻的freed chunk进行合并,合并了之后将它插入到unsorted bin中。
