前言
fuzz解析数据的库函数的方法一般是找一个简单的二进制来测试库函数的功能,通过生成不同的输入来不断地运行该二进制程序。一般是通过fork和execve来生成子进程运行目标二进制程序,fuzz程序通过waitpid()函数来等待子进程退出,如果子进程发出SIGSEGV或SIGABORT等信号,则证明子进程崩溃了,此时可能会发生了memory corruption bugs。然而没有一个输入,就调用ececve()函数来进行程序的链接,库函数的初始化等操作,大大地降低了fuzzing的效率[1]。AFL通过在目标程序中插入fork server的逻辑代码来保证在fuzzing的时候只进行一次程序的链接,库函数的初始化等操作,而通过fork()函数的copy-on-write机制,大大提高了fuzzing的效率。
fork server
通过在二进制程序中插入fork server代码,该fork server会在main函数之前执行,它会暂停,等待AFL fuzzing端的输入,当AFL fuzzing端”发号施令”给fork server之后,fork server此时就通过fork()函数来生成子进程,子进程继续main函数的逻辑,由于fork server已经将各种资源都加载好,所以每次子进程只需要执行main函数的代码即可。
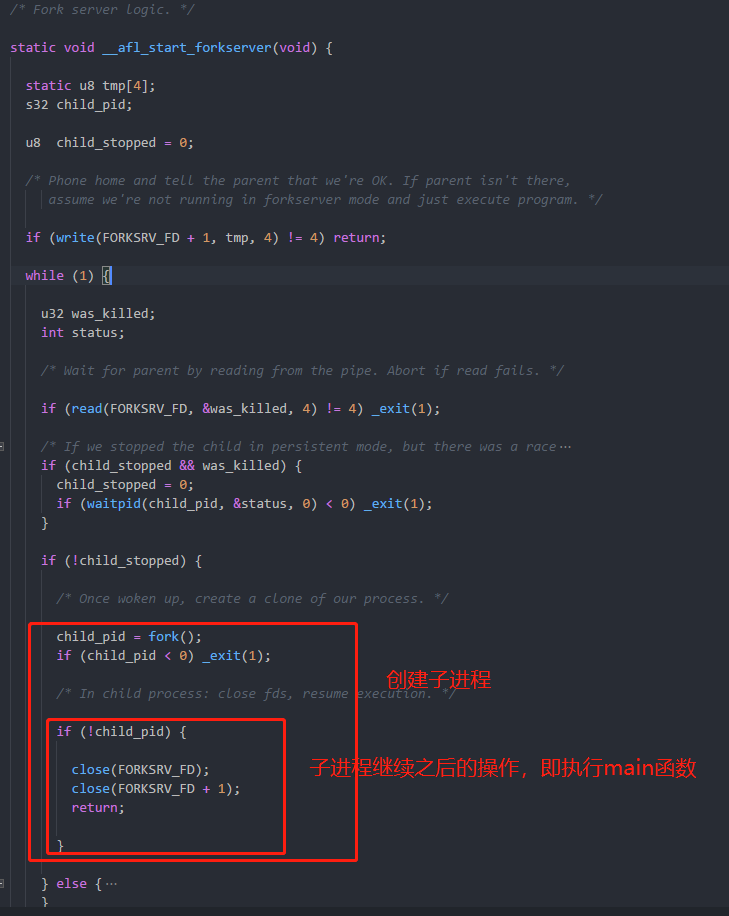
上面的例子是在afl中的llvm_mode文件夹中的afl-llvm-rt.o.c文件中定义的,fork server的逻辑也是比较简单,一个while循环,从FORKSRV_FD文件中读取AFL端给传来的数据,其中FORKSRV_FD是一个管道的一端,负责从AFL端读取数据。如果AFL端传来数据,则证明此时AFL的输入已准备好,则可以通过fork()来生成一个子进程,来运行main函数,进行fuzzing。
由于AFL进程与要fuzzing的进程不是父子关系(AFL与fork server是父子关系,fork server与要fuzzing的进程是父子关系)。所以AFL通过管道与fork server进程进行通信,而fork server通过waitpid()函数等待要fuzzing的子进程完成,得到其退出是的状态status,并将status通过管道传给AFL进程。
其中在afl-fuzz.c中的init_forkserver函数中,是对管道进行的初始化,感兴趣的可以看一下。
引用
- Fuzzing random programs without execve(). https://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html